Using a Conditional Diffusion Model for Stock Price Prediction
Author: Joshua Hughes
Abstract
Predicting financial time series is difficult because the data is noisy and doesn't follow a set pattern. This paper explains a way to predict stock prices using a type of model called a Conditional Score-based Diffusion model for Imputation, or CSDI. This model can create a range of possible future prices, which gives a better sense of the potential risks and rewards. We show that the model can create realistic price distributions and talk about how it could be used for automated trading.
1. Introduction
Predicting stock prices has always been a major focus in finance. Older models like ARIMA and GARCH are still used, but they can have trouble with the complex and unpredictable nature of the stock market. Newer deep learning models, like Recurrent Neural Networks and Transformers, are better at this, but they still have a hard time dealing with the market's uncertainty.
This paper looks at using a CSDI model to predict stock prices. CSDI is a type of generative model that has done well in other areas, like creating images and audio. We use this model for time-series forecasting, where it can learn from past data to create a set of possible future price paths. This method gives a more complete picture of the future than a single prediction, which is important for managing risk and making decisions.
2. Background on Diffusion Models
Diffusion models are a type of model that learns how to reverse a process of adding noise to data. The basic idea is to take a piece of data, add a little bit of random noise to it over and over again, and then teach a model how to undo that process. This reverse process can then be used to create new data, starting from just noise.
2.1. The Forward Process
The forward process is what adds noise to the data. It's a series of steps that adds a small amount of Gaussian noise at each step. If you have a piece of data \(x_0\), the forward process looks like this:
Here, \(\beta_t\) is a small number that controls how much noise is added at each step. One useful thing about this process is that you can figure out what the data will look like at any step \(t\) with a single formula:
In this formula, \(\alpha_t = 1 - \beta_t\), \(\bar{\alpha}_t\) is the product of all the \(\alpha_s\) values up to step \(t\), and \(\epsilon\) is just random noise.
2.2. The Reverse Process
The reverse process is where the model learns to remove the noise from the data. The goal is to learn the probability of the previous step's data given the current step's data, or \(p_\theta(x_{t-1} | x_t)\). This is hard to figure out directly, but it can be estimated with a Gaussian distribution:
The model is trained to predict the noise that was added to the data. The way it learns is by trying to minimize the difference between the noise it predicted and the actual noise that was added. This is usually done with a mean squared error loss function:
3. Using CSDI for Stock Price Prediction
In this project, we use the CSDI model to predict stock prices. The model is given historical stock data and uses it to predict what the price will do in the future. The model is built using a Transformer, which is a good choice for data that comes in a sequence.
3.1. Model Architecture
The model has two parts: a context encoder and a denoising network. The context encoder is a Transformer network that looks at the historical stock data and creates a summary of it, called a context vector. The denoising network is another Transformer network that takes the noisy future data and the context vector and tries to predict the noise that was added.
Using a Transformer is helpful because it can find connections between data points that are far apart in time, which is important for financial data. The self-attention part of the Transformer lets the model decide which parts of the past data are most important for making a prediction.
3.2. Data Preprocessing
The raw OHLCV data is changed to make it easier for the model to use. First, we calculate the log returns of the prices and volume. This makes the data more stable and easier to work with. Then, the log returns are normalized so that they have a mean of zero and a standard deviation of one. This is a common step in machine learning that helps the model learn better.
4. Results and Discussion
The model was trained on a set of historical stock prices for a few different companies. After it was trained, we used it to make predictions about future price movements. The picture below shows a prediction for the stock ABT.
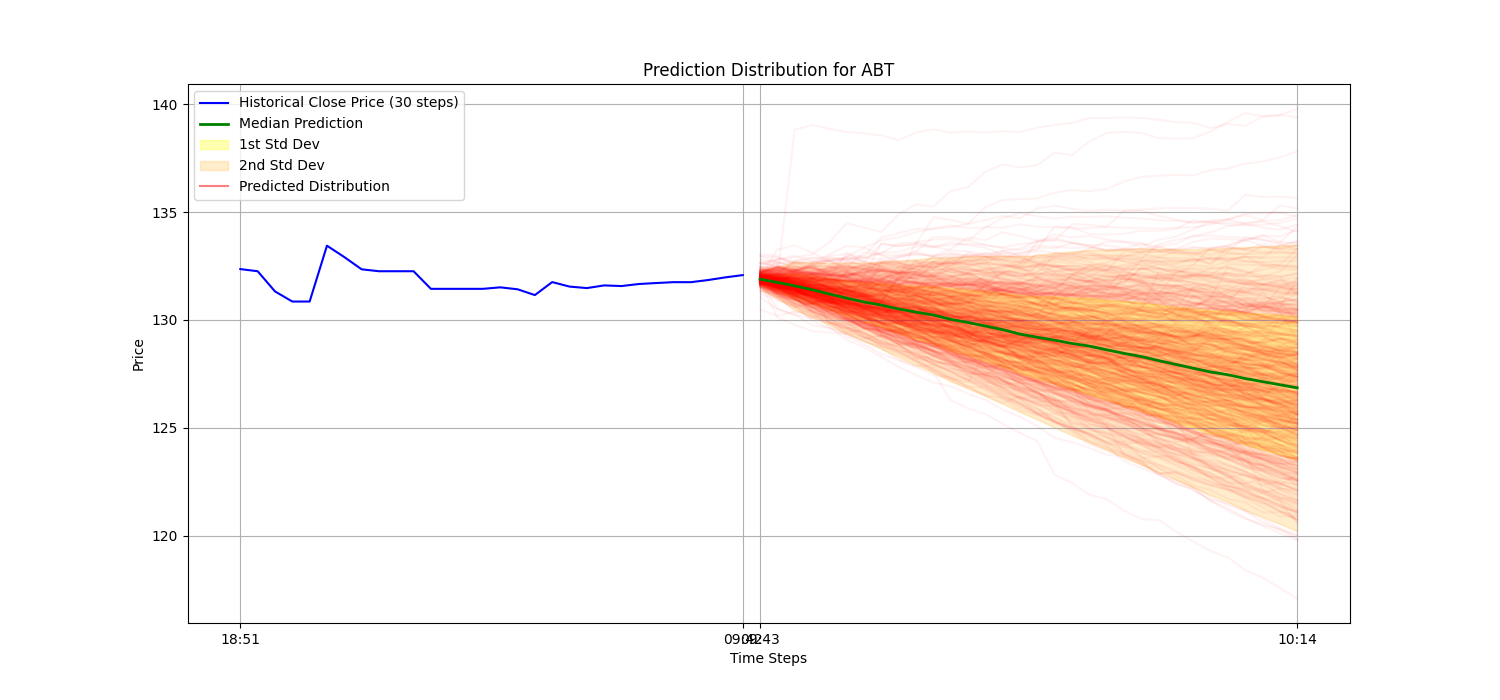
Figure 1: Prediction Distribution for ABT. The blue line is the historical price, the green line is the median prediction, and the red lines are a number of possible future price paths.
The results show that the model can create a believable range of future price paths. The median prediction follows the general trend of the stock price, and the width of the distribution shows how uncertain the prediction is. This kind of probabilistic forecast can help with making better trading decisions. For example, a trader could use the distribution to decide where to set stop-loss and take-profit orders, or to figure out the chances of a certain price change.
5. Conclusion
This paper has shown how a CSDI model can be used to predict stock prices. The model can create a probabilistic forecast of future price movements, which gives a more complete picture of the future than a single prediction. The results show that the model can create realistic price distributions, and a trading analyzer can use this distribution to create trading signals. In the future, we could try out different model designs, add more features to the model, and test how well the trading signals would have worked in the past.